Weakly Supervised Semantic Segmentation via Alternate Self-Dual Teaching
Problem Statement
Weakly supervised semantic segmentation (WSSS) is a challenging yet important research field in vision community. In WSSS, the key problem is to generate high-quality pseudo segmentation masks (PSMs).
Existing approaches mainly depend on the discriminative object part to generate PSMs, which would inevitably miss object parts or involve surrounding image background, as the learning process is unaware of the full object structure. In fact, both the discriminative object part and the full object structure are critical for deriving of high-quality PSMs.
Proposed Method
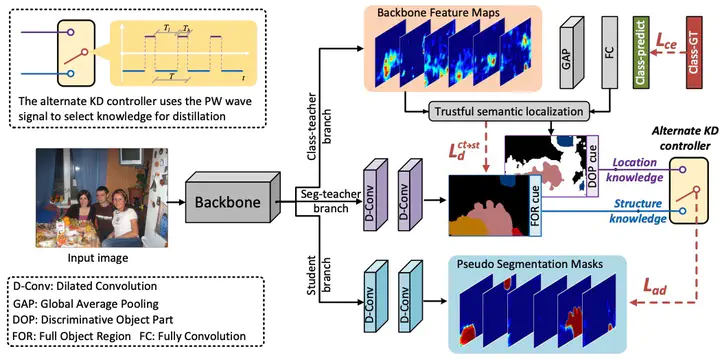
To fully explore these two information cues, we build a novel end-to-end learning framework, alternate self-dual teaching (ASDT), based on a dual-teacher single-student network architecture. The information interaction among different network branches is formulated in the form of knowledge distillation (KD).
Unlike the conventional KD, the knowledge of the two teacher models would inevitably be noisy under weak supervision. Inspired by the Pulse Width (PW) modulation, we introduce a PW wave-like selection signal to alleviate the influence of the imperfect knowledge from either teacher model on the KD process.
Key Contributions
1. Dual-Teacher Architecture: We propose a novel dual-teacher single-student network architecture that explores both discriminative object parts and full object structures simultaneously.
2. PW Modulation Mechanism: Inspired by Pulse Width modulation, we introduce a selection signal to filter out noisy knowledge during the knowledge distillation process, ensuring high-quality pseudo mask generation.
3. End-to-End Learning: The entire framework is trained end-to-end, allowing seamless information flow and optimization across all network components.
Experimental Results
Comprehensive experiments on the PASCAL VOC 2012 and COCO-Stuff 10K demonstrate the effectiveness of the proposed ASDT framework, and new state-of-the-art results are achieved.
The proposed method successfully balances the trade-off between capturing discriminative features and maintaining complete object structures, leading to significantly improved segmentation quality in weakly supervised scenarios.